
What is Big Data?
Imagine a mega coffee shop that serves thousands every minute. Orders are flying in from apps, kiosks, drive-throughs, and foot traffic. Some are regular cappuccinos, others are double-shot, soy, iced, sugar-free, with a twist. This chaos is what big data looks like:
| Concept | Coffee Shop Analogy |
|---|---|
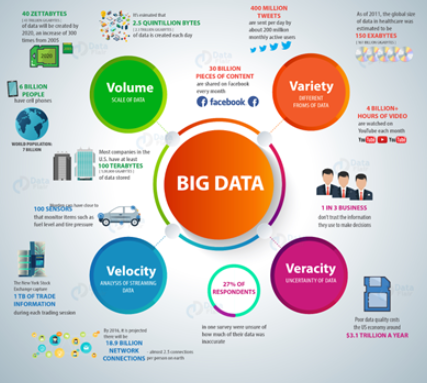
| Volume | Hundreds of customers/hour (huge amounts of data) |
| Velocity | New orders flying in every second (fast data) |
| Variety | Orders in all forms — text, voice, app, etc. |
| Veracity | Some orders are wrong/confusing (dirty data) |
| Value | Use the order trends to upsell — more profits! |
Big Data isn’t just a lot of data — it’s messy, fast, and coming from all directions. And like a great café, you need a smart system to keep up.
💥 Common Mistakes in Big Data (And What They Look Like in a Café)
| Mistake | Coffee Shop Version | Fix |
|---|---|---|
| No backup system | Barista forgets your order; no paper trail | Build redundancy — backup pipelines, fault-tolerant storage |
| Not cleaning data | Mixing salt instead of sugar | Use data validation, cleaning, and transformation steps |
| Bottlenecks | One barista makes all drinks | Use distributed systems — parallel processing |
| Ignoring change | Recipe changes, but barista uses old one | Add schema versioning, automation checks |
| Poor security | Customers taking any drink from the shelf | Use encryption, authentication, role-based access |
🛠️ How to Handle Big Data Like a Pro Café
Just like a café needs the right tools, systems, and processes, so does a big data pipeline:
| Step | Coffee Shop Equivalent | Tools & Best Practices |
|---|---|---|
| Ingest data | Order kiosks, online apps | Kafka, Kinesis, RabbitMQ |
| Process in real-time | Baristas making custom drinks fast | Apache Flink, Apache Spark Streaming |
| Store safely | Fridge with labels + expiry dates | Delta Lake, Parquet files, S3, HDFS |
| Serve to apps | Waiters delivering drinks to the right people | gRPC, REST APIs, Airflow |
| Monitor everything | Cameras checking order speed + errors | Prometheus, Grafana |
| Automate responses | Smart fridge reorders milk when low | Auto-scaling, error handling, alerting systems |
🚀 Example Use Case: Auto-Training ML Pipeline for E-Commerce
Customer Orders = Data Recommending Products = ML Model
🧠 The Business Need:
An e-commerce store wants to recommend items based on browsing and purchase history — but trends change fast.
☕ The Coffee Analogy:
- Every time a customer walks in (data arrives), their preferences change.
- The café retrains its memory — now it knows everyone wants oat milk this week.
- The baristas (ML model) update automatically without being told.
🛠️ The Real Tech Setup:
- Kafka — captures real-time customer actions (like order queue)
- Flink — streams the data into features for the model (real-time processing)
- Delta Lake — stores both raw and processed data with version tracking
- MLflow — handles model training and versioning
- Airflow — triggers model re-training when new data is enough
- SageMaker or TensorFlow Serving — serves the latest model to users
💡 Bonus: Add a feedback loop — customer clicks or skips a recommendation? That becomes training data too.
✅ Final Sip: What to Always Remember
| Principle | Coffee Shop Equivalent |
|---|---|
| Redundancy | Two espresso machines in case one breaks |
| Scalability | Add more baristas during rush hour |
| Automation | Smart fridge reorders beans |
| Observability | Know what went wrong when an order fails |
| Flexibility | Can switch menus fast when trends change |
Big Data = Coffee Shop at Scale You don’t just serve fast — you serve smart, with every system in place to handle growth, chaos, and surprises.