
Monte Carlo Simulation and Stock Prices Forecasting
Introduction
Monte Carlo Simulation is a mathematical technique used in modeling the probability of different outcomes especially where there is uncertainty or randomness of variables.
Monte Carlo simulation helps in providing an understanding of the impact of risk and uncertainty in prediction and forecasting models.
The simulations makes an assumption of the existence of perfectly efficient markets where there exists symmetry of information and no investor can gain from having information that others do not have.
Financial Markets have an element of risk which therefore requires analysis of each possible risk factor. There the simulation help model every single possible outcome.
Monte Carlo simulation make forecasts in the face of uncertainty by using multiple values and ultimately finding the averages of the results as opposed to other methods that replace the uncertain variable with a single average number.
Put simply, Monte Carlo Simulation makes several trials with randomized values generated from an underlying distribution of uncertain variable.
Prediction and Forecasting using Monte Carlo Simulation
To predict todays price, we need yesterdays price multiplied by the exponential growth factor
\[S_t = S_{t-1} \ * e^r\]where:
- \(S_t\) represents the price today
- \(S_{t-1}\) represents yesterdays price
- \(e^r\) represents the exponential growth factor. This is the missing information which requires Monte Carlo simulation to obtain
As a first step there is need to estimate the returns before performing any simulations to obtain the exponential growth factor.
To estimate the return we bring in Geometric Brownian motion concept which is the stochastic process for modeling random behavior over time. Brownian motion has two components that is:
- Drift component which is the expected return of the asset (the directional trend over time) \(Drift = \ (\mu -\frac{1}{2} \sigma^2 \ )\)
- Volatility Component which represents the variability of the assets price (As we know stock prices experience volatility) \(Volatility = \ ( \sigma Z[Rand(0;1)] \ )\)
When we incorporate the drift and the volatility component we can get the exponential growth term r as shown below $$ \ ( r = \left( \mu - \frac{1}{2} \sigma^2 \right ) + \sigma Z[Rand(0; 1)] \ )
$$
With the above equation we can compute the daily return since we have now defined the exponential growth term r
\[\ ( S_t = S_{t-1} \times e^{\left( \mu - \frac{1}{2} \sigma^2 \right) + \sigma Z[Rand(0; 1)]} \ )\]Implementation in Python
First import the data from yahoo finance (This is free and doesn’t require any token)
This analysis used Meta, Google and Apple stock prices
1
2
3
4
5
6
7
8
9
# import the libraries (make sure to install the libraries before importation)
import yfinance as yf
import numpy as np
import pandas as pd
from pandas_datareader import data as wb
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
This first part uses Google stock prices alone before simulation
1
2
3
4
5
6
7
8
9
10
11
12
# import your data
ticker = 'GOOG'
data = pd.DataFrame()
data[ticker] = yf.download(ticker, start = '2010-01-01')['Adj Close]
#Plot
data.plot(figsize=(15,6))
# X and y labels
plt.title("Google Stock Price Over Time (2010 - 2024)")
plt.xlabel("Date")
plt.ylabel("Adjusted Close Price (USD)")
plt.show()

- Interpretation: There seems to be an upward trend in google stock prices with periods of volatility. The general upward trend is often viewed favorably by investors because it signifies growth.
Compute the logarithmic form of the returns to make it more symmetric
1
2
3
4
5
6
7
8
9
log_return = np.log(1 + data['GOOG'].pct_change())
# Drop any NaN values
log_return = log_return.dropna()
#Plot
sns.histplot(log_return, kde=True, bins=50)
plt.xlabel("Daily Return")
plt.ylabel("Frequency")

The graph shows the presence of outliers in the data despite the daily return being centred around zero. This is a characteristic that is common in financial markets because of the presence of volatility.
We then calculate the drift to help analyze the behavior of the stock return and modeling the stock prices movements
1
2
3
u = log_return.mean()
var = log_return.var()
drift = u - (0.5*var)
Recall that to do the simulations we need to compute the variance and the daily returns. Therefore generate random variables for every forecast and simulation we will be running.
1
2
3
4
5
6
7
# We compute the variance and the daily returns to run the simulations
stdev = log_return.std()
days = 50
trials = 10000
Z = norm.ppf(np.random.rand(days, trials))
# Calculate daily returns using the drift and standard deviation
daily_returns = np.exp(drift + stdev * Z)
The above function returns an array of random variables which we use for our simulations
1
2
3
4
5
#We then need to calculate a stock price for each trial that we are going to run in the simulations
price_paths = np.zeros_like(daily_returns)
price_paths[0] = data.iloc[-1]
for t in range(1, days):
price_paths[t] = price_paths[t-1]*daily_returns[t]
Note: The for loop represents our equation where we were calculating todays price as function of yesterdays price and the exponential growth factor which had the drift term and the standard deviation as its components.
The function above runs the simulations and therefore can help us calculate profitability or expected annualized returns as shown below.
For this next step we can automate the process to include as many stocks as one may want and run simulations on as many stocks as one may want. To do this we will use the Capital Asset Pricing Model (CAPM)
The introduction of the CAPM represents the introduction of the systematic risk (the beta) and the risk free asset aspect
We first go through the process of data importation again and this time we use Meta, Apple and Google stock prices.
1
2
3
4
5
6
7
8
9
10
def import_stock_data(tickers, start='2010-01-01'):
data = pd.DataFrame()
if isinstance(tickers, str): # If a single ticker is passed as a string
tickers = [tickers] # Convert to list to handle the single ticker case
for t in tickers:
data[t] = yf.download(t, start=start)['Adj Close']
return data
#This part imports the data we will be using
data = import_stock_data(["META", "GOOG", "AAPL"], start='2005-01-01')
We then follow the earlier procedure and compute the log of the returns
1
2
3
4
5
def log_returns(data):
return (np.log(1+data.pct_change()))
log_return = log_returns(data)
Calculate the drift term
1
2
3
4
5
6
7
8
9
10
11
12
#Calculate the drift
def drift_calc(data):
lr = log_returns(data)
u = lr.mean()
var = lr.var()
drift = u-(0.5*var)
try:
return drift.values
except:
return drift
drift_calc(data)
Calculate the daily returns with 1000 iterations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def daily_returns(data, days, iterations):
ft = drift_calc(data) # Drift, assumed to have shape (3,)
stv = log_returns(data).std()
# Check if the standard deviation (stv) is a scalar or an array
if np.isscalar(stv):
stv = np.array(stv).reshape(1, 1, 1) # Convert scalar to array and reshape for broadcasting
else:
stv = stv.values.reshape(-1, 1, 1) # Reshape array for broadcasting
# Reshape `ft` to (3, 1, 1) so it can broadcast with (3, 50, 1000)
ft = ft.reshape(-1, 1, 1)
# Generate random normal values and calculate returns
dr = np.exp(ft + stv * norm.ppf(np.random.rand(days, iterations)))
return dr
daily_returns(data,50,1000)
This function integrates market index data with an existing data set of stock prices, ensuring that the data aligns by date
1
2
3
4
5
6
7
8
9
10
11
12
def market_data_combination(data, mark_ticker="^GSPC", start='2010-1-1'):
# Import market data
market_data = import_stock_data([mark_ticker], start=start)
# Ensure that the indices match on date, and then combine the two datasets
combined_data = data.join(market_data, how='inner')
# Calculate the average market return (mean return of the market index)
market_returns = log_returns(combined_data[[mark_ticker]])
market_avg_return = market_returns.mean()[0]
return combined_data, market_avg_return
Function computes key risk and performance metrics (Beta, CAPM, and Sharpe Ratio) for a portfolio of assets relative to a specified market index.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def beta_sharpe(data, mark_ticker="^GSPC", start='2010-1-1', riskfree=0.025):
# Combine data with market index
dd, mark_ret = market_data_combination(data, mark_ticker, start)
log_ret = log_returns(dd)
# Calculate annualized covariance and variance
covar = log_ret.cov() * 252 # Annualized covariance
covar = pd.DataFrame(covar.iloc[:-1, -1]) # Take covariance with market returns
mrk_var = log_ret.iloc[:, -1].var() * 252 # Annualized market variance
# Calculate Beta
beta = covar / mrk_var
beta.columns = ['Beta'] # Explicitly name the column as 'Beta'
# Calculate standard deviation for Sharpe ratio
stdev_ret = pd.DataFrame((log_ret.std() * 252**0.5)[:-1], columns=['STD']) # Annualized std dev
# Merge Beta and Standard Deviation (STD)
beta = beta.merge(stdev_ret, left_index=True, right_index=True)
# Calculate CAPM and Sharpe Ratio
beta['CAPM'] = riskfree + (beta['Beta'] * (mark_ret - riskfree))
beta['Sharpe'] = (beta['CAPM'] - riskfree) / beta['STD']
print(beta.head())
return beta
beta_sharpe(data, mark_ticker="^GSPC", start='2010-01-01')
Function determines the probability of the last set of predicted values meeting a certain condition based on either their returns or their absolute values.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
def probs_find(predicted, higherthan, on='value'):
# Check if 'predicted' is a DataFrame with at least two rows and columns
if predicted.empty or len(predicted) < 2:
raise ValueError("The 'predicted' DataFrame must contain at least two rows for comparison.")
# Handle the case when the 'on' parameter is 'return'
if on == 'return':
predicted0 = predicted.iloc[0, 0] # Initial value for comparison (first row, first column)
predicted_last = predicted.iloc[-1] # Last row of the DataFrame
predList = list(predicted_last)
# Calculate returns relative to the initial value
over = [i for i in predList if ((i - predicted0) * 100) / predicted0 >= higherthan]
less = [i for i in predList if ((i - predicted0) * 100) / predicted0 < higherthan]
# Handle the case when the 'on' parameter is 'value'
elif on == 'value':
predicted_last = predicted.iloc[-1] # Last row of the DataFrame
predList = list(predicted_last)
# Compare predicted values to the higherthan threshold
over = [i for i in predList if i >= higherthan]
less = [i for i in predList if i < higherthan]
else:
raise ValueError("'on' must be either 'value' or 'return'")
total_predictions = len(over) + len(less)
if total_predictions == 0:
return 0
# Return the probability (proportion of 'over' values to total)
return len(over) / total_predictions
probs_find(data, 0.5, on='return')
This is supposed to return a single value. In this case the function returned a probability of 1.0 which implies that 100% of the predicted values have returns greater than or equal to 0.5%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
def daily_returns(data, days, iterations):
# Calculate the daily percentage returns for each stock
log_returns = np.log(1 + data.pct_change()).dropna() # Compute log returns
mean_returns = log_returns.mean().values
std_returns = log_returns.std().values
num_stocks = len(data.columns)
# Generate random returns for each stock over the simulation period
simulated_returns = np.random.normal(loc=mean_returns, scale=std_returns, size=(days, iterations, num_stocks))
return simulated_returns
def simulate_mc(data, days, iterations, plot=True):
num_stocks = len(data.columns)
# Generate daily returns with the correct shape (days, iterations, num_stocks)
returns = daily_returns(data, days, iterations)
# Create an empty 3D matrix for price simulation: (days, iterations, num_stocks)
price_list = np.zeros((days, iterations, num_stocks))
# Initialize with the last prices for each stock
last_prices = data.iloc[-1].values
price_list[0, :, :] = last_prices # Set last prices for each stock across all iterations
# Calculate the price for each day and stock
for t in range(1, days):
print(f"Price list at t={t}: {price_list[t-1].shape}")
print(f"Returns at t={t}: {returns[t].shape}") # Updated to access correct slice
price_list[t] = price_list[t-1] * (1 + returns[t]) # Multiply prices by (1 + daily returns)
if plot:
# Example: plotting the last day's prices for the first stock
x = pd.DataFrame(price_list[:, :, 0]).iloc[-1] # Get the last day's prices for the first stock
fig, ax = plt.subplots(1, 2, figsize=(14, 4))
sns.histplot(x, kde=True, ax=ax[0]) # Use histplot instead of distplot
sns.histplot(x, cumulative=True, kde=True, ax=ax[1]) # Use histplot instead of distplot
plt.xlabel("Stock Price")
plt.show()
try:
[print(nam) for nam in data.columns]
except:
print(data.name)
print(f"Days: {days - 1}")
print(f"Expected Value: ${round(pd.DataFrame(price_list[:, :, 0]).iloc[-1].mean(), 2)}") # First stock example
print(f"Return: {round(100 * (pd.DataFrame(price_list[:, :, 0]).iloc[-1].mean() - price_list[0, 0, 0]) / pd.DataFrame(price_list[:, :, 0]).iloc[-1].mean(), 2)}%")
print(f"Probability of Breakeven: {probs_find(pd.DataFrame(price_list[:, :, 0]), 0, on='return')}")
return pd.DataFrame(price_list[:, :, 0]) # Returning prices for the first stock as an example
simulate_mc(data, 252, 1000, plot=True)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
def monte_carlo(tickers, days_forecast, iterations, start_date='2000-01-01', plotten=False):
data = import_stock_data(tickers, start=start_date)
inform = beta_sharpe(data, mark_ticker="^GSPC", start=start_date)
simulatedDF = []
# Check if the columns "Beta", "Sharpe", and "CAPM" exist in 'inform'
if not all(col in inform.columns for col in ['Beta', 'Sharpe', 'CAPM']):
raise KeyError("One or more required columns ('Beta', 'Sharpe', 'CAPM') are missing from 'inform'.")
for t in range(len(tickers)):
y = simulate_mc(data[[tickers[t]]], (days_forecast + 1), iterations) # Adjusted here
if plotten:
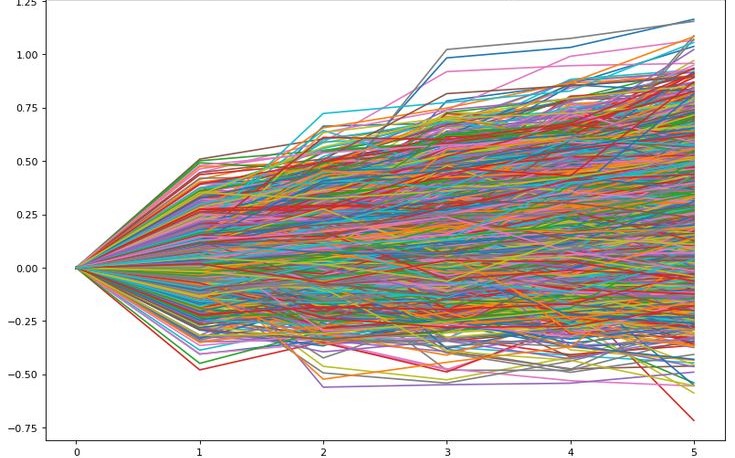
forplot = y.iloc[:, 0:10]
forplot.plot(figsize=(15, 4))
# Using .loc[] to avoid indexing errors
print(f"Beta: {round(inform.loc[tickers[t], 'Beta'], 2)}")
print(f"Sharpe: {round(inform.loc[tickers[t], 'Sharpe'], 2)}")
print(f"CAPM Return: {round(100 * inform.loc[tickers[t], 'CAPM'], 2)}%")
y['ticker'] = tickers[t]
cols = y.columns.tolist()
cols = cols[-1:] + cols[:-1] # Move 'ticker' to the first column
y = y[cols]
simulatedDF.append(y)
simulatedDF = pd.concat(simulatedDF)
return simulatedDF
ret_sim_df = monte_carlo(["META", "GOOG", "AAPL"], 252, 10000, start_date='2015-1-1')

- Left Histogram: Indicates a non-normal distribution of simulated returns (the distribution is skewed to the right). This implies the potential of getting high returns .
- Right CDF: Shows the cumulative distribution of stock prices. This implies that most of the prices fall below the higher thresholds, with fewer simulations resulting in very high prices/returns.
In conclusion, Monte Carlo simulations has various applications including predicting stock prices using stochastic modeling because of the presence of volatility in stock and financial markets. With the use of python libraries, this blog automated the simulation process and visualized potential outcomes for Meta, Google and Apple. These kind of simulation enable the assessment of probabilities, risk level and helps in developing strategies to counter risks.
References
https://www.investopedia.com/terms/m/montecarlosimulation.asp
https://medium.com/analytics-vidhya/monte-carlo-simulations-for-predicting-stock-prices-python-a64f53585662